Sorting data is a common need in many applications. If you have thought about writing your own sorting routine, you likely came up with a scheme that picked the first data item, and then compared it to each of the other elements to find a smaller value (if sorting into ascending order) or a larger value (if sorting into descending order). Finding a match, you switch the two values in your list of data.
Gradually, as you scan the list, the smallest (or largest) value bubbles up to the front of the list. Once the whole list is scanned, you have found the smallest (or largest) value and switched it to the beginning.
Then you would start with the next data value and compare it to the remaining data values. And so on.
Great idea if you came up with this – seriously! In computer science algorithms, this is known as the “bubble sort”. It works fine – but it has one problem – as the number of items to be sorted grows, the time it takes to do the sort grows even faster.
In fact, we say that a bubble sort runs in a time proportional to n^2 (n squared). If there are 10 items to sort, this will take 10^2 or 100 time units to sort.
If there are 30 items to sort, this will take 30^2 or 900 time units to sort. Just going from 10 items to 30 items adds 800 time units to our sorting time! Ouch!
As you can see, the bubble sort is simple but it can take a long time to run!
Computer scientists have invented other ways to sort data. One of the best known has the descriptive name “QuickSort”. In many cases, it’s sorting time is on the order of n ln n (that is n times the natural logarithm of n).
If we compare that to the Bubble Sort for n=10, we get 23 time units and for n=30, we get 103 time units. As you can see, QuickSort is much faster than the Bubble Sort.
There are two drawbacks, though. QuickSort is not super intuitive and if the data is ordered in the worst possible way before we start the sorting process, the worst case for QuickSort can also be n^2 time. But for most of our typical sorting applications on a nice set of relatively random data, QuickSort is quite fast.
This tutorial will be a little different as I am not going to go in to details as to how QuickSort does its magic. Briefly, instead of sorting the entire list of data, it splits the list in roughly half – calling these partitions. Each of these is also split in half, as many times as needed, in a process known as recursion. This is not the place to explain recursion either unfortunately! But the basic idea is that we call QuickSort for our full data set, and then Quicksort partitions the data into two pieces and calls QuickSort on both halves. For those not familiar with recursion, that may seem a bit odd or at least magical.
If you would like to learn more, this QuickSort tutorial with sample Java and C++ code is really great. I took the sample Java code and translated that into MIT App Inventor.
Using This Code
I have loaded the sample code into the MIT Gallery where you can get a copy.
I do not recommended trying to enter this code by hand. There are many little things you can end up doing incorrectly, like using i when you should use j – they all sort of look a like. Debugging this code, particularly if you are not familiar with the QuickSort algorithm, is difficult.
To use this routine, all you need to do is to create a list with your data. I have set this up so that it uses a “list of lists”. Think of this as being like a list containing a last name and a score value, like this:
1 = Abraham, 91
2 = Martinez, 87
3 = Nguyen, 83
4 = Indara, 93
and so on.
Basically, each element in the list is a data record. If we wanted to, we could make our list contain records holding an address book like contact record:
1 = Abraham, John, 123 Main St, BigCity, Ohio, USA
When it comes to sorting a list containing records, we often wish to choose which part of the data record to use to sort. Do we sort by last name? By first name? By city?
With my QuickSort code, you can choose which item to use for the sort order by specifying a “column” value.
In the example record above, the last name is stored in column 1, the first name in column 2, and the city name in column 4.
To sort by first name, we would do the equivalent of
QuickSort (Data, 1, size of list, 2)
where Data contains our set of data, 1 and size of list specifies the start and end of our list of data, and 2 is the column number. (Corrected: earlier version showed column 4, not column 2 – fixed.)
Pretty simple to use!
The only slightly difficult part is setting up the list of data. We will see how this is done, below.
User View
The app starts by showing the unsorted data list.

After pressing the Sort Data button, we have sorted the data by name (column 1) and the sorted list is updated on the display:

Designer View
The user interface contains a single button and a text label. Since the text label’s text field has been set to blank, we cannot see it in the screen capture. It’s just below the Sort Data button!

You can see it in the Components list, though:

Selecting the Properties of lblSortedData shows that Text has been set to blank.

Blocks View
We store our data records in a global variable DataToSort:
![]()
In the app’s Screen1.Initialize handler, we set up the list as a “list of lists”. Here, some sample data is set up for demonstrating the code.

When the Sort Data button is pressed, we call the QuickSort procedure to sort the data, and then call the DisplayData procedure to update the screen. Note that this code sorts the data by column 1 – or the last name. To sort this list by the numeric values instead, use column 2.

Our DisplayData procedure is simple. Using the for each control block, our code cycles through the entire list and copies the data to the lblSortedData text field. We use the special character “n” to insert a new line in the middle of the text between each record.

Now we get to the QuickSort procedure. As described briefly, earlier, QuickSort divides the data set in to a left and right partition. This is done by calling a procedure named Partition and then calling QuickSort to sort the two halves (when a procedure or function calls itself, this is called recursion).

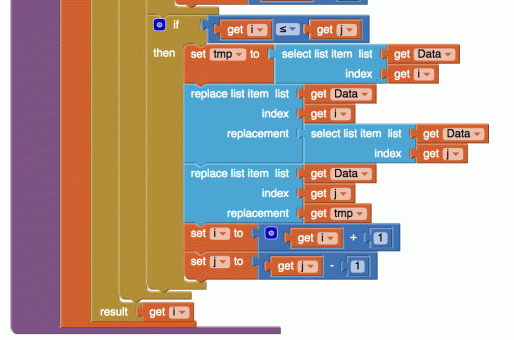
The Partition procedure is too big for one screen capture so it has been split into two sections.

Note – this code sorts values into ascending order. If you would like to sort into descending values, you need to change the two comparisons, above. Where you see “get Data < get pivot”, this should change to “get Data > get pivot”. And where you see “get Data > get pivot” in the second while test block, change this to “get Data < get pivot”.
And then here is the remainder of the code. When we have found a value that is “out of order” we switch the values in the data set here:
Access Source Code at MIT App Gallery
Access code here (link fixed on April 12)

Thanks for it!
LikeLike